浙江大学交互式数据小组巫英才老师指导,主要研究不同类型的可视化图表在用户理解层面的难易程度,以及导致认知难度的因素。
项目背景
近年来,视觉分析(VA)成为一个快速发展的领域,许多新颖的工具被设计用于广泛的分析任务。虽然这些工具可能比过去的工具提供了更好的效率,但是它们也为不熟悉新颖可视化工具的用户带来了额外的学习工作。在接受和信任这些可视化之前,人们需要首先理解它们。然而,理解不熟悉的可视化对用户来说并不容易。
这样的困难主要在于两方面:
- 一些面向专业用户的可视化本身在格局和原理上就十分复杂:
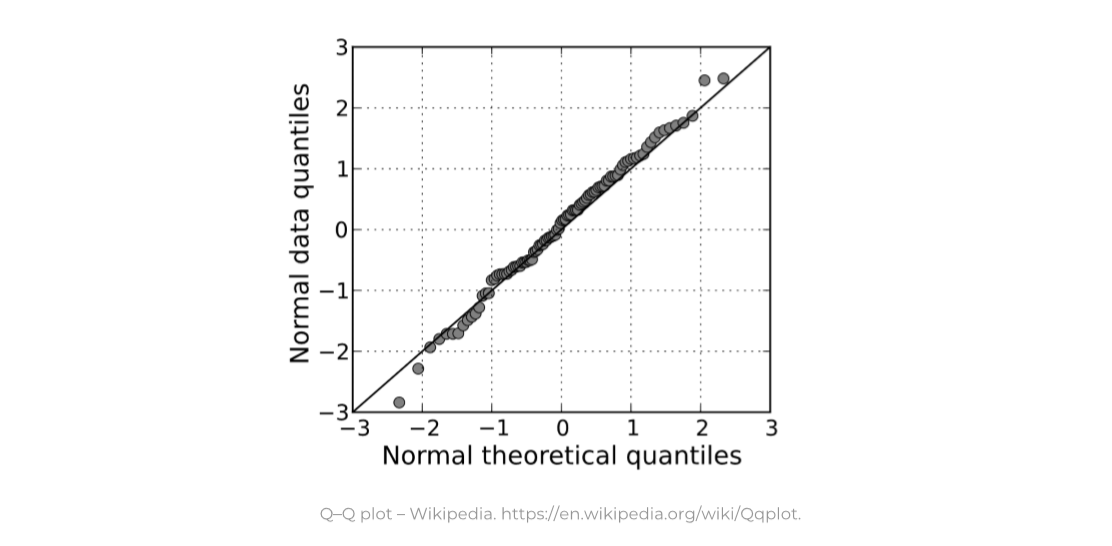
- 部分可视化初看并不复杂,但却隐藏着理解偏差的问题。例如qq-plot ,实验证明很多观察者会将其简单归属为散点图,而忽视了它的分位数原理以及分布拟合规则。
相关工作
目前,在这方面的研究大多更侧重于人对于可视化图表的感知,即对于视觉通道的反映准确率;很少有人研究用户在面对不熟悉的图表时的认知表现如何,即对于图表元素的语义理解。
例如下图中,若被试者能够意识到各个BMI占比大小,即完成了感知任务;能够准确说出BMI占比背后的地区健康水平,才算实现认知准确。
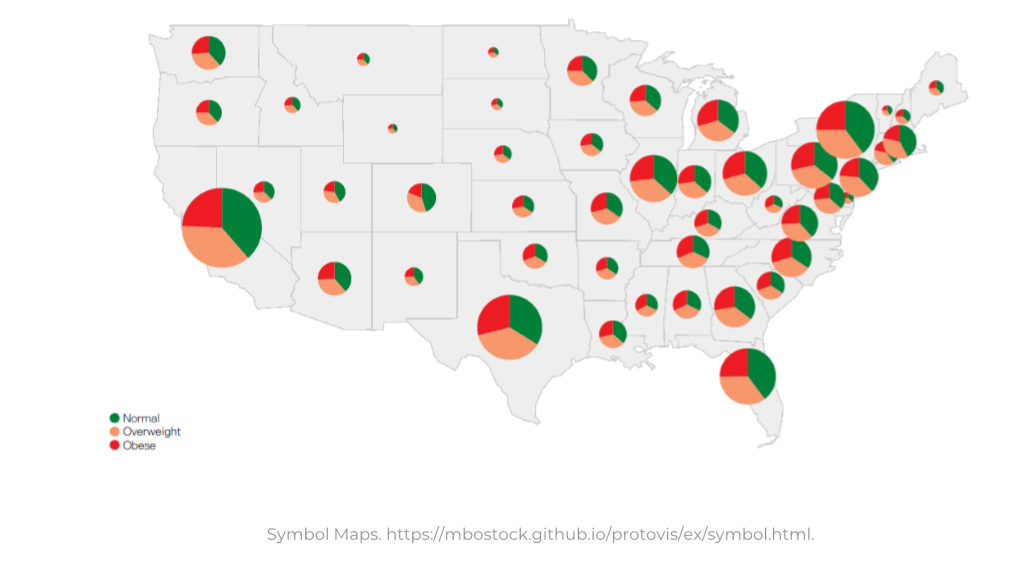
我们的项目希望研究的是心理学模型和可视化呈现的内在联系,为此我们进行了第一个前置实验。
实验设计
1. 实验材料
本实验的目的在于研究不同类型的可视化图表在用户理解层面的难易程度,以及探究是什么因素导致了认知难度。
我们首先根据论文中关于可视化图表的分类,调研了5大类,共18小类的可视化图表,从中挑选出最具有代表性的每小类5个样本,总计90个实例作为测试数据集。
我们利用随机生成50套图表组合,保证每10个被试可以覆盖数据集中的所有样本。

2. 实验流程
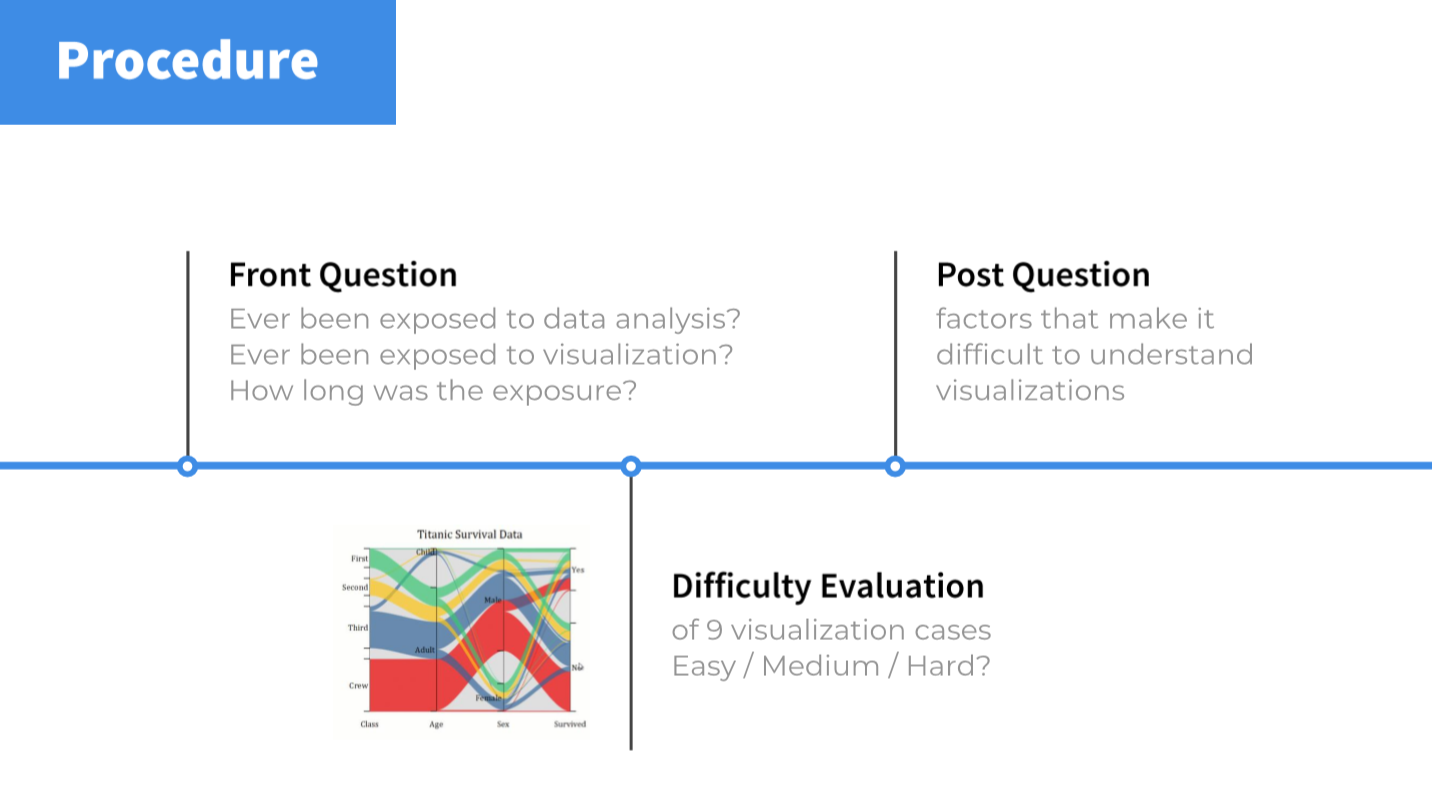
随后,我们找到覆盖了 31 个不同专业的、男女比将近 1:1 的 50 个浙大学生作为被试,以一对一、面对面(单人时长 20 分钟的)访谈形式完成用户测试。

我们在测试中,首先以问答的形式了解被试的数据分析以及可视化经验,随后依次呈现9个图表,以描述标题、主被试交流的模式,最终得到被试对于图表难易程度的等级量化评价。
最后我们得到被试关于“什么因素会导致理解困难”的主观总结,作为后续实验结果分析的一个重要参照。
实验结果
1. 整体分析
我们的实验结果如下:
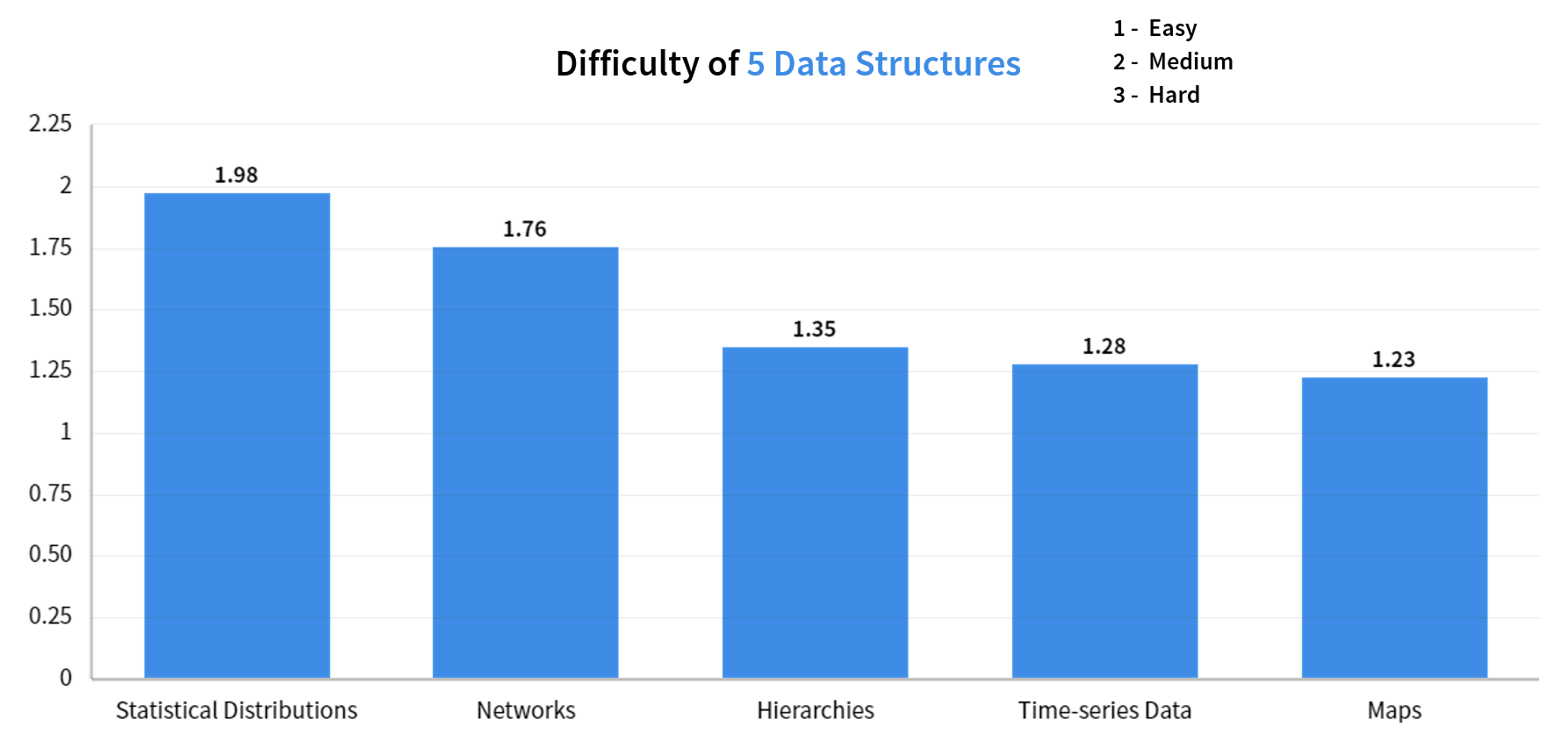
首先,我们分别给难懂、中等和易懂三个级别赋分 3、2、1,然后将所有被试对于每一类图评分进行平均。
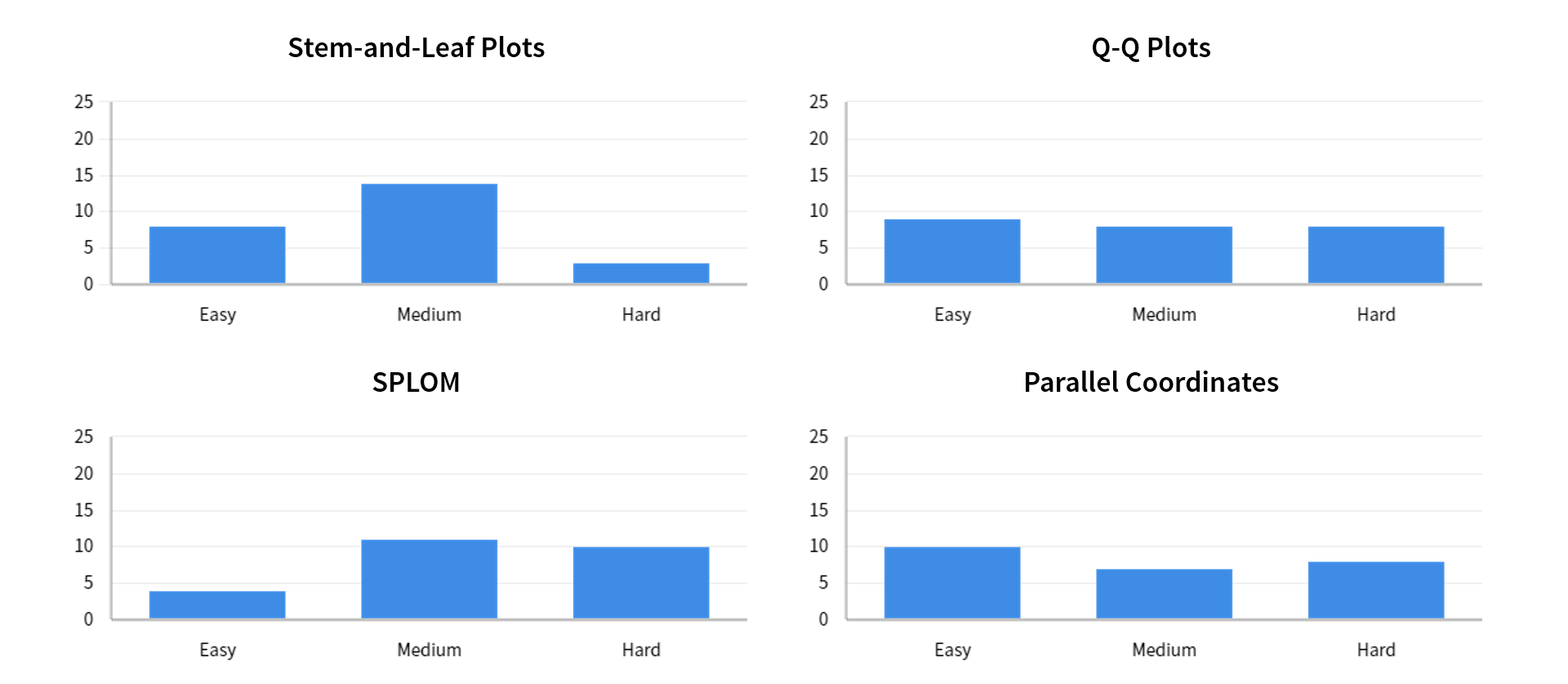
就 5 大类可视化图表而言,统计分布图和网络类图的难度系数最大的,随后是层次结构图以及时间序列图, 而 maps 被认为是最简单的一类可视化。
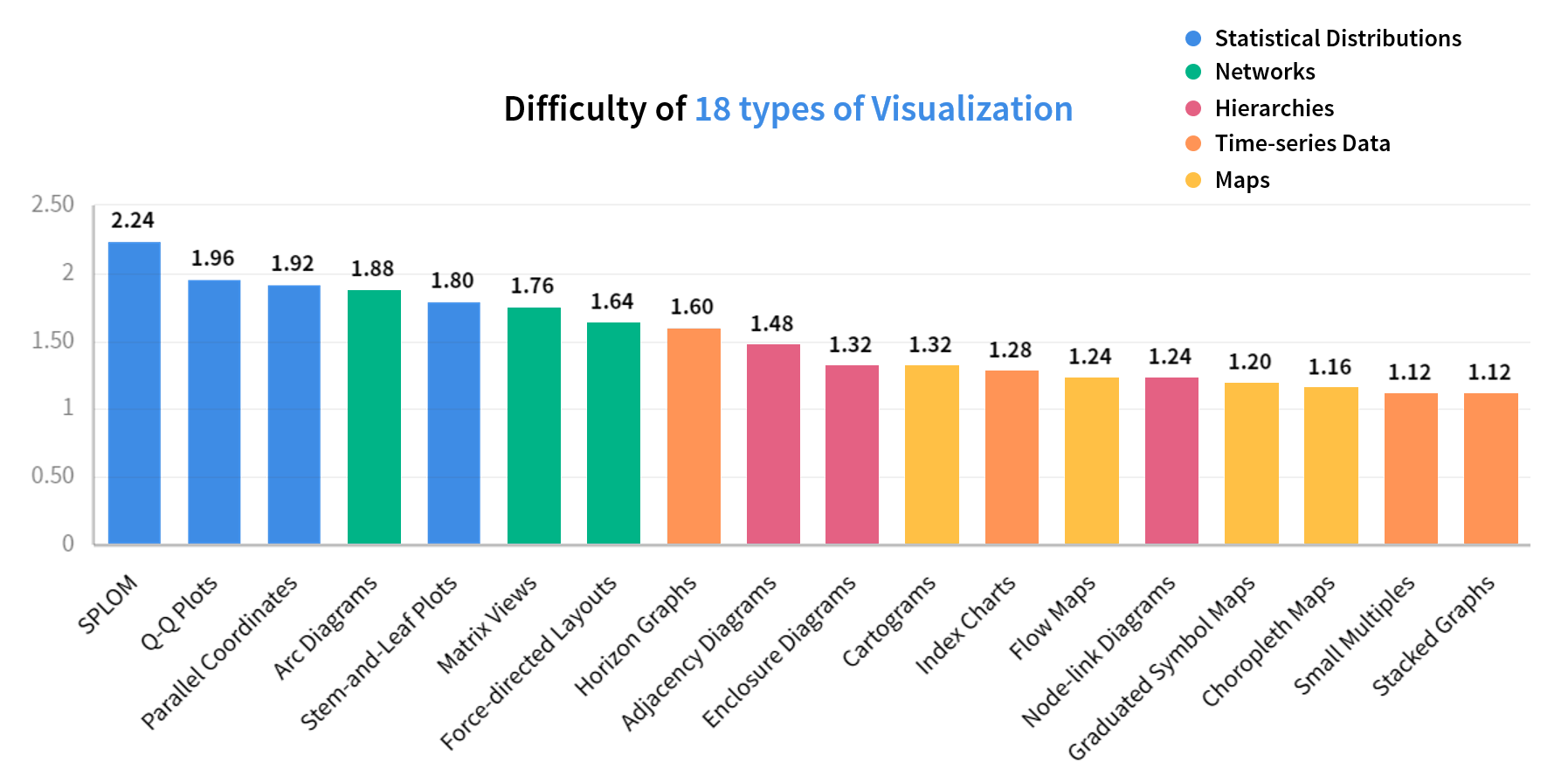
如果我们细看所有小类的难度系数排行,那么SPLOM即散点图矩阵一马当先,它的难度系数几乎是最简单的堆叠图的两倍。
将最难的大类中的每个小类的难度等级分布拿出来看,会发现有单峰和平均两种分布形态。
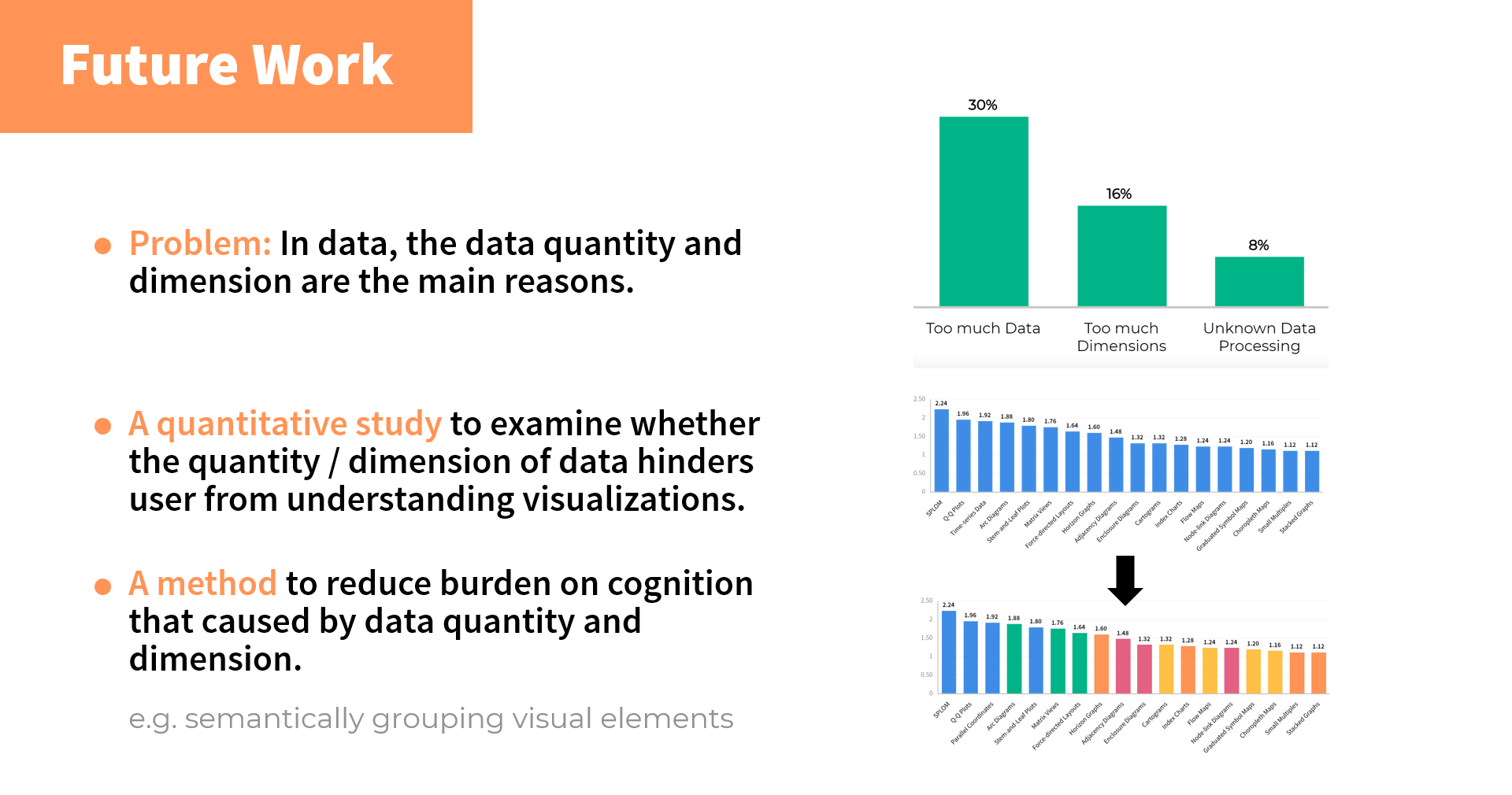
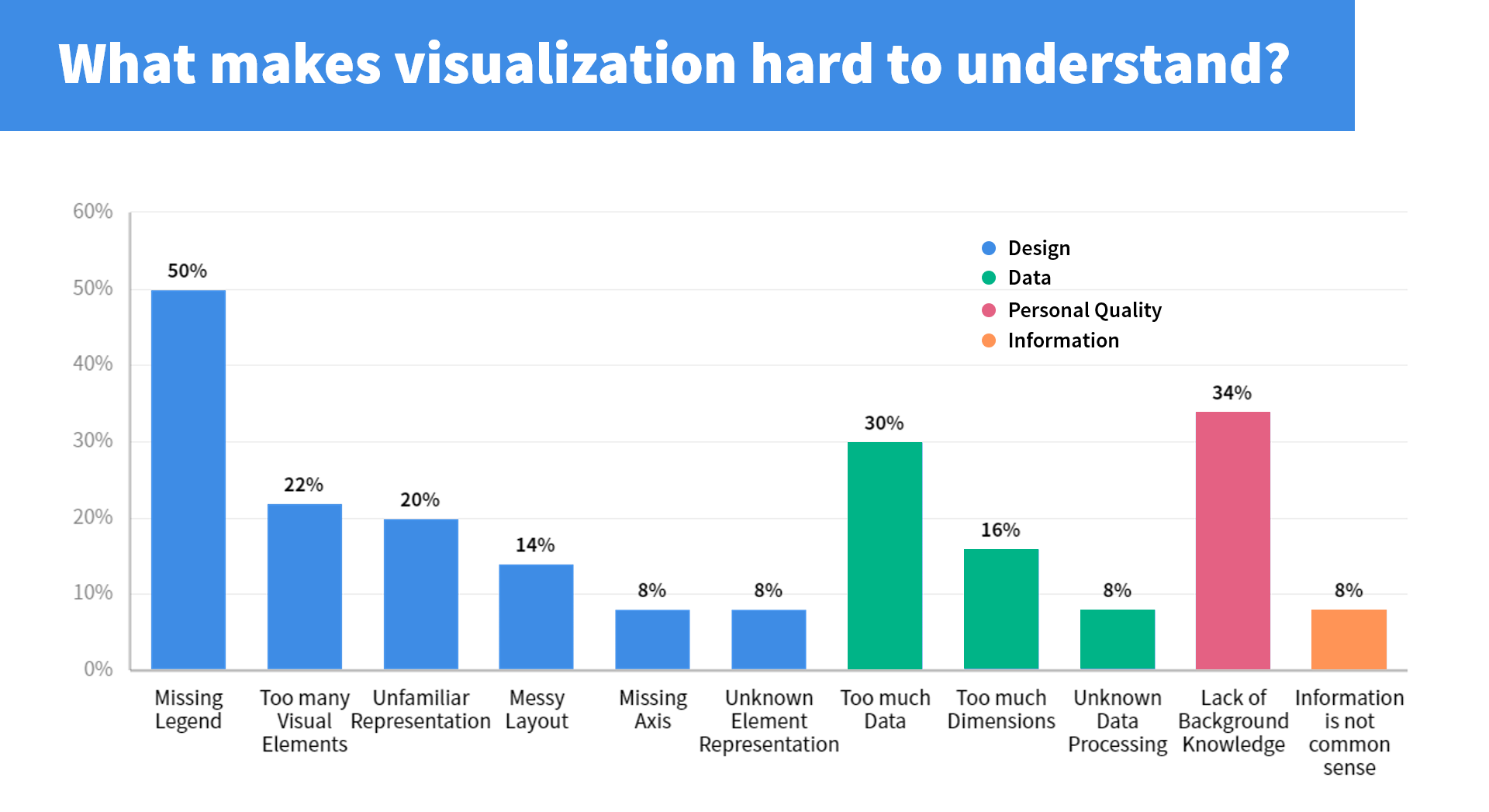
另一个有意义的结果是,如实验设计所说,我们对所有被试提出了一个“关于可视化图表中什么因素会导致难以理解”的问题,将收到的反馈聚类分布,我们看到:图设计因素方面,图例的缺少是最大的理解障碍,占50%;在数据层面,过大的数据量以及过高的数据维度成为最主要的问题。被试者个人素质层面,缺乏对于图表的背景知识也会较大程度地阻碍理解。
2. 外部因素
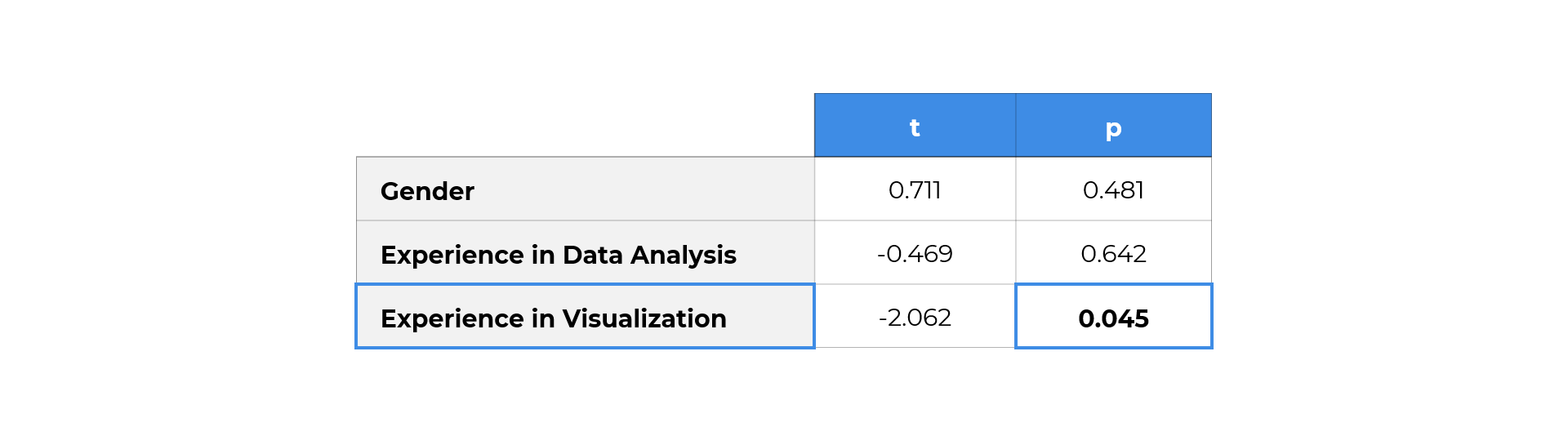
另外,我们利用t-test检验,发现,可视化经验会显著影响用户对于图表的理解难易程度,性别、数据分析能力与结果则并未呈现相关性。
3. 特例分析
最后,我们被反馈为最难的散点图矩阵类进行特例分析:
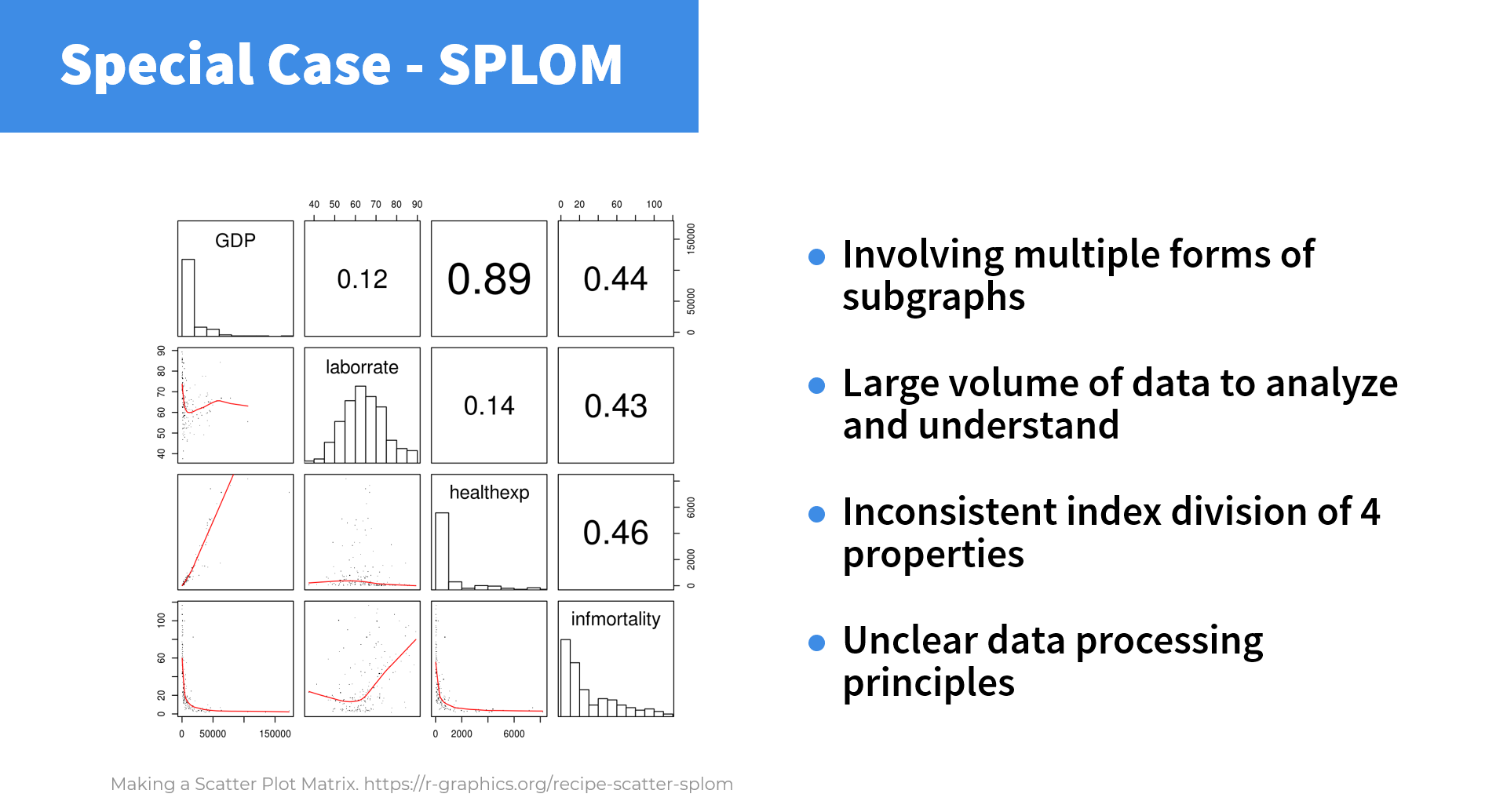
我们认为造成它难度的原因主要有以下几点:
- 整个图中涉及多类子图,组成复杂且用了并不常见的对角化呈现方式。
- 需要分析和理解的数据体量较大,使得用户一开始无法抓到问题重点,产生信息冗余的困惑。
- 各个坐标轴分度不一致,用户难以在不同的度量中实现思维切换。
- 数据处理原理不清。图表并没有显式给出右上方相关系数的定义和计算方式,这对于没有数据分析经验的用户来说,是一个极大的挑战。
未来工作
根据以上的实验结果,我们发现:在数据层面,数据体量和数据维度是最主要的因素。
针对这一点,我们将进一步展开更为严谨的定量实验,来研究可视化中的“数据量”以及“数据维度”对用户理解程度产生的影响。并且尝试去探究如何优化可视化设计,以减少这些因素对于理解的障碍。